Valid DP-203 Dumps shared by ExamDiscuss.com for Helping Passing DP-203 Exam! ExamDiscuss.com now offer the newest DP-203 exam dumps, the ExamDiscuss.com DP-203 exam questions have been updated and answers have been corrected get the newest ExamDiscuss.com DP-203 dumps with Test Engine here:
Access DP-203 Dumps Premium Version
(365 Q&As Dumps, 35%OFF Special Discount Code: freecram)
<< Prev Question Next Question >>
Question 106/165
You have data stored in thousands of CSV files in Azure Data Lake Storage Gen2. Each file has a header row followed by a properly formatted carriage return (/r) and line feed (/n).
You are implementing a pattern that batch loads the files daily into an enterprise data warehouse in Azure Synapse Analytics by using PolyBase.
You need to skip the header row when you import the files into the data warehouse. Before building the loading pattern, you need to prepare the required database objects in Azure Synapse Analytics.
Which three actions should you perform in sequence? To answer, move the appropriate actions from the list of actions to the answer area and arrange them in the correct order.
NOTE: Each correct selection is worth one point

You are implementing a pattern that batch loads the files daily into an enterprise data warehouse in Azure Synapse Analytics by using PolyBase.
You need to skip the header row when you import the files into the data warehouse. Before building the loading pattern, you need to prepare the required database objects in Azure Synapse Analytics.
Which three actions should you perform in sequence? To answer, move the appropriate actions from the list of actions to the answer area and arrange them in the correct order.
NOTE: Each correct selection is worth one point
Correct Answer:
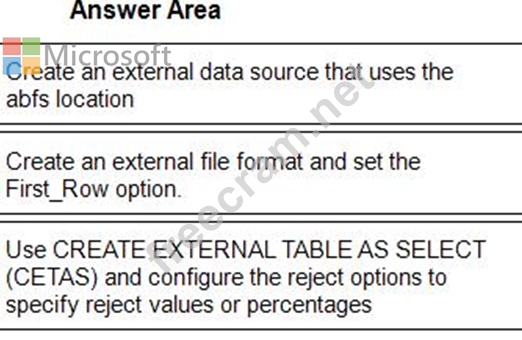
1 - Create an external data source that uses the abfs location
2 - Create an external file format and set the First_Row option.
3 - Use CREATE EXTERNAL TABLE AS SELECT (CETAS) and configure the reject options to specify reject values or percentages Reference:
https://docs.microsoft.com/en-us/sql/relational-databases/polybase/polybase-t-sql-objects
https://docs.microsoft.com/en-us/sql/t-sql/statements/create-external-table-as-select-transact-sql


- Question List (165q)
- Question 1: You have an Azure data factory. You execute a pipeline that ...
- Question 2: Vou have an Azure Data factory pipeline that has the logic f...
- Question 3: You are designing an application that will store petabytes o...
- Question 4: You have a SQL pool in Azure Synapse. You plan to load data ...
- Question 5: You have an Azure subscription that contains an Azure Synaps...
- Question 6: You have two fact tables named Flight and Weather. Queries t...
- Question 7: You have an Azure subscription that contains an Azure Synaps...
- Question 8: You have an Azure subscription that contains an Azure Synaps...
- Question 9: You have an Azure Stream Analytics job that read data from a...
- Question 10: You have an Azure Data Factory instance that contains two pi...
- Question 11: Note: This question is part of a series of questions that pr...
- Question 12: You are designing an Azure Data Lake Storage solution that w...
- Question 13: You have an Azure subscription. You need to deploy an Azure ...
- Question 14: You need to schedule an Azure Data Factory pipeline to execu...
- Question 15: You are building an Azure Synapse Analytics dedicated SQL po...
- Question 16: You are designing a folder structure for the files m an Azur...
- Question 17: In Azure Data Factory, you have a schedule trigger that is s...
- Question 18: You have an Azure Data Lake Storage Gen2 account named adls2...
- Question 19: You have an Azure subscription that contains the resources s...
- Question 20: You need to create an Azure Data Factory pipeline to process...
- Question 21: You have an Azure Data Factory pipeline named pipeline1 that...
- Question 22: You need to implement an Azure Databricks cluster that autom...
- Question 23: You have an Azure Synapse Analytics workspace. You plan to d...
- Question 24: You have an Azure Blob storage account named storage! and an...
- Question 25: You have files and folders in Azure Data Lake Storage Gen2 f...
- Question 26: You have an Azure subscription that contains an Azure Databr...
- Question 27: You have an Azure subscription that contains a storage accou...
- Question 28: You plan to monitor an Azure data factory by using the Monit...
- Question 29: You have an Azure subscription that contains an Azure data f...
- Question 30: You have an Azure Synapse Analytics dedicated SQL pool named...
- Question 31: You have an Azure Storage account and a data warehouse in Az...
- Question 32: You have a data model that you plan to implement in a data w...
- Question 33: You are building an Azure Stream Analytics job to retrieve g...
- Question 34: You develop a dataset named DBTBL1 by using Azure Databricks...
- Question 35: A company purchases IoT devices to monitor manufacturing mac...
- Question 36: You configure monitoring for a Microsoft Azure SQL Data Ware...
- Question 37: You have an Azure Data Factory pipeline that performs an inc...
- Question 38: You store files in an Azure Data Lake Storage Gen2 container...
- Question 39: You have an Azure Synapse Analytics dedicated SQL pool named...
- Question 40: You are designing an application that will use an Azure Data...
- Question 41: You are developing an application that uses Azure Data Lake ...
- Question 42: You are designing a financial transactions table in an Azure...
- Question 43: You plan to ingest streaming social media data by using Azur...
- Question 44: You are designing an Azure Synapse Analytics dedicated SQL p...
- Question 45: You are building an Azure Analytics query that will receive ...
- Question 46: You are designing a statistical analysis solution that will ...
- Question 47: You have an enterprise data warehouse in Azure Synapse Analy...
- Question 48: You are designing an Azure Synapse Analytics workspace. You ...
- Question 49: Note: This question is part of a series of questions that pr...
- Question 50: You need to design a data retention solution for the Twitter...
- Question 51: You have an Azure Synapse Analytics dedicated SQL pool. You ...
- Question 52: Note: This question is part of a series of questions that pr...
- Question 53: You have an Azure Synapse serverless SQL pool. You need to r...
- Question 54: You plan to create an Azure Data Factory pipeline that will ...
- Question 55: You have an Azure subscription that contains an Azure Data L...
- Question 56: You have an Azure Data Factory pipeline that has the activit...
- Question 57: You have an Azure Data Lake Storage Gen2 account that contai...
- Question 58: What should you recommend using to secure sensitive customer...
- Question 59: You have an Azure Synapse Analytics pipeline named Pipeline1...
- Question 60: You need to implement versioned changes to the integration p...
- Question 61: You have an activity in an Azure Data Factory pipeline. The ...
- Question 62: You are designing an Azure Data Lake Storage Gen2 structure ...
- Question 63: You have an Azure Databricks workspace named workspace1 in t...
- Question 64: you have a project in Azure DevOps that contains a repositor...
- Question 65: You have a self-hosted integration runtime in Azure Data Fac...
- Question 66: You have an Azure Synapse Analytics dedicated SQL Pool1. Poo...
- Question 67: You need to trigger an Azure Data Factory pipeline when a fi...
- Question 68: You are designing a monitoring solution for a fleet of 500 v...
- Question 69: You plan to create a real-time monitoring app that alerts us...
- Question 70: You need to design an Azure Synapse Analytics dedicated SQL ...
- Question 71: You have an Azure subscription that contains an Azure Synaps...
- Question 72: You have an Azure subscription that contains a logical Micro...
- Question 73: You have an Azure Data Factory pipeline named pipeline1 that...
- Question 74: You are designing an enterprise data warehouse in Azure Syna...
- Question 75: You have an Azure Data Factory pipeline named Pipeline1!. Pi...
- Question 76: You have the following Azure Data Factory pipelines * ingest...
- Question 77: You have an Azure Synapse Analytics workspace named WS1 that...
- Question 78: You have a trigger in Azure Data Factory configured as shown...
- Question 79: You have an Azure SQL database named Database1 and two Azure...
- Question 80: You use Azure Data Factory to create data pipelines. You are...
- Question 81: You have a SQL pool in Azure Synapse. You discover that some...
- Question 82: You are planning the deployment of Azure Data Lake Storage G...
- Question 83: Note: This question is part of a series of questions that pr...
- Question 84: You need to build a solution to ensure that users can query ...
- Question 85: You have an Azure subscription that contains an Azure Cosmos...
- Question 86: From a website analytics system, you receive data extracts a...
- Question 87: You are planning a solution to aggregate streaming data that...
- Question 88: You have an Azure Active Directory (Azure AD) tenant that co...
- Question 89: You are designing an Azure Synapse solution that will provid...
- Question 90: You have an enterprise data warehouse in Azure Synapse Analy...
- Question 91: You are designing a solution that will copy Parquet files st...
- Question 92: You have an Azure subscription that contains a Microsoft Pur...
- Question 93: Note: This question is part of a series of questions that pr...
- Question 94: You have an Azure subscription that contains an Azure Synaps...
- Question 95: You have an Apache Spark DataFrame named temperatures. A sam...
- Question 96: You are designing an enterprise data warehouse in Azure Syna...
- Question 97: You have an Azure Synapse Analytics workspace that contains ...
- Question 98: You have an Azure Synapse Analytics dedicated SQL pool that ...
- Question 99: You have two fact tables named Flight and Weather. Queries t...
- Question 100: You have an Azure Synapse Analytics dedicated SQL pool mat c...
- Question 101: You have an Azure subscription that contains an Azure Synaps...
- Question 102: You have an Azure Databricks workspace that contains a Delta...
- Question 103: You need to design a data storage structure for the product ...
- Question 104: You have an Azure Data Lake Storage Gen2 container. Data is ...
- Question 105: You are creating an Azure Data Factory data flow that will i...
- Question 106: You have data stored in thousands of CSV files in Azure Data...
- Question 107: You have two Azure Storage accounts named Storage1 and Stora...
- Question 108: You are designing an Azure Databricks interactive cluster. T...
- Question 109: You have a C# application that process data from an Azure Io...
- Question 110: You have a table in an Azure Synapse Analytics dedicated SQL...
- Question 111: You have an enterprise data warehouse in Azure Synapse Analy...
- Question 112: You need to design a data ingestion and storage solution for...
- Question 113: You have an Azure Data Factory pipeline that is triggered ho...
- Question 114: Note: This question is part of a series of questions that pr...
- Question 115: You have an Azure Synapse Analytics SQL pool named Pool1 on ...
- Question 116: You need to design a data retention solution for the Twitter...
- Question 117: You use Azure Stream Analytics to receive Twitter data from ...
- Question 118: You are designing 2 solution that will use tables in Delta L...
- Question 119: You have an on-premises data warehouse that includes the fol...
- Question 120: A company has a real-time data analysis solution that is hos...
- Question 121: You have an Azure Data Lake Storage account that has a virtu...
- Question 122: You have an Azure Synapse Analytics dedicated SQL pool that ...
- Question 123: You need to collect application metrics, streaming query eve...
- Question 124: You build a data warehouse in an Azure Synapse Analytics ded...
- Question 125: You have an Azure subscription that contains an Azure Synaps...
- Question 126: You have an Azure Synapse Analytics dedicated SQL pool. You ...
- Question 127: You have an Azure Data Lake Storage Gen2 container that cont...
- Question 128: You need to design a solution that will process streaming da...
- Question 129: You have the following Azure Stream Analytics query. (Exhibi...
- Question 130: You have an Azure Stream Analytics query. The query returns ...
- Question 131: You have an Azure Factory instance named DF1 that contains a...
- Question 132: You have a Microsoft Purview account. The Lineage view of a ...
- Question 133: You are designing a slowly changing dimension (SCD) for supp...
- Question 134: You have an Azure Synapse Analytics serverless SQL pool name...
- Question 135: You plan to implement an Azure Data Lake Gen2 storage accoun...
- Question 136: You plan to perform batch processing in Azure Databricks onc...
- Question 137: What should you recommend to prevent users outside the Litwa...
- Question 138: You plan to create a table in an Azure Synapse Analytics ded...
- Question 139: You are designing the folder structure for an Azure Data Lak...
- Question 140: Note: This question is part of a series of questions that pr...
- Question 141: You are designing a data mart for the human resources (MR) d...
- Question 142: Note: This question it part of a series of questions that pr...
- Question 143: You have an Azure Data Lake Storage Gen2 account named accou...
- Question 144: Vou have an Azure Synapse Analytics dedicated SQL pool. You ...
- Question 145: You are planning a streaming data solution that will use Azu...
- Question 146: You have an Azure Data Lake Storage account that contains CS...
- Question 147: You have an Azure data factory named ADM. You currently publ...
- Question 148: You have several Azure Data Factory pipelines that contain a...
- Question 149: You are designing a highly available Azure Data Lake Storage...
- Question 150: You are processing streaming data from vehicles that pass th...
- Question 151: You have an Azure Data Factory that contains 10 pipelines. Y...
- Question 152: You use Azure Data Factory to prepare data to be queried by ...
- Question 153: You need to implement a Type 3 slowly changing dimension (SC...
- Question 154: You have the following table named Employees. (Exhibit) You ...
- Question 155: You have an Azure Data Factory version 2 (V2) resource named...
- Question 156: You have an Azure subscription that contains an Azure Synaps...
- Question 157: You have an Azure Synapse Analytics dedicated SQL pool named...
- Question 158: You have an Azure Synapse Analystics dedicated SQL pool that...
- Question 159: You have an Azure subscription that contains an Azure Databr...
- Question 160: You are designing a highly available Azure Data Lake Storage...
- Question 161: You have an Azure subscription that contains an Azure data f...
- Question 162: You are designing a date dimension table in an Azure Synapse...
- Question 163: You have an Azure SQL database named DB1 and an Azure Data F...
- Question 164: You are designing an Azure Databricks table. The table will ...
- Question 165: You have an Azure Databricks resource. You need to log actio...
