<< Prev Question Next Question >>
Question 5/69
You are designing an Azure Data Factory solution that will download up to 5 TB of data from several REST APIs.
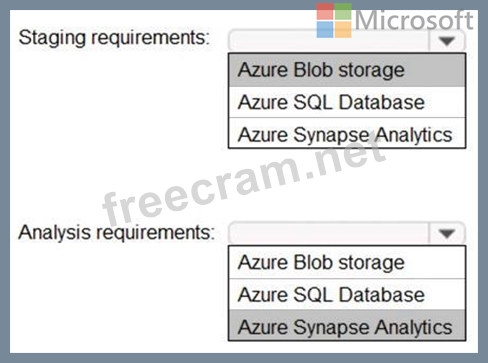
The solution must meet the following staging requirements:
* Ensure that the data can be landed quickly and in parallel to a staging area.
* Minimize the need to return to the API sources to retrieve the data again should a later activity in the pipeline fail.
The solution must meet the following analysis requirements:
* Ensure that the data can be loaded in parallel.
* Ensure that users and applications can query the data without requiring an additional compute engine.
What should you include in the solution to meet the requirements? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.

The solution must meet the following staging requirements:
* Ensure that the data can be landed quickly and in parallel to a staging area.
* Minimize the need to return to the API sources to retrieve the data again should a later activity in the pipeline fail.
The solution must meet the following analysis requirements:
* Ensure that the data can be loaded in parallel.
* Ensure that users and applications can query the data without requiring an additional compute engine.
What should you include in the solution to meet the requirements? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.