Valid DP-200 Dumps shared by ExamDiscuss.com for Helping Passing DP-200 Exam! ExamDiscuss.com now offer the newest DP-200 exam dumps, the ExamDiscuss.com DP-200 exam questions have been updated and answers have been corrected get the newest ExamDiscuss.com DP-200 dumps with Test Engine here:
Access DP-200 Dumps Premium Version
(242 Q&As Dumps, 35%OFF Special Discount Code: freecram)
<< Prev Question Next Question >>
Question 53/80
You develop data engineering solutions for a company.
A project requires an in-memory batch data processing solution.
You need to provision an HDInsight cluster for batch processing of data on Microsoft Azure.
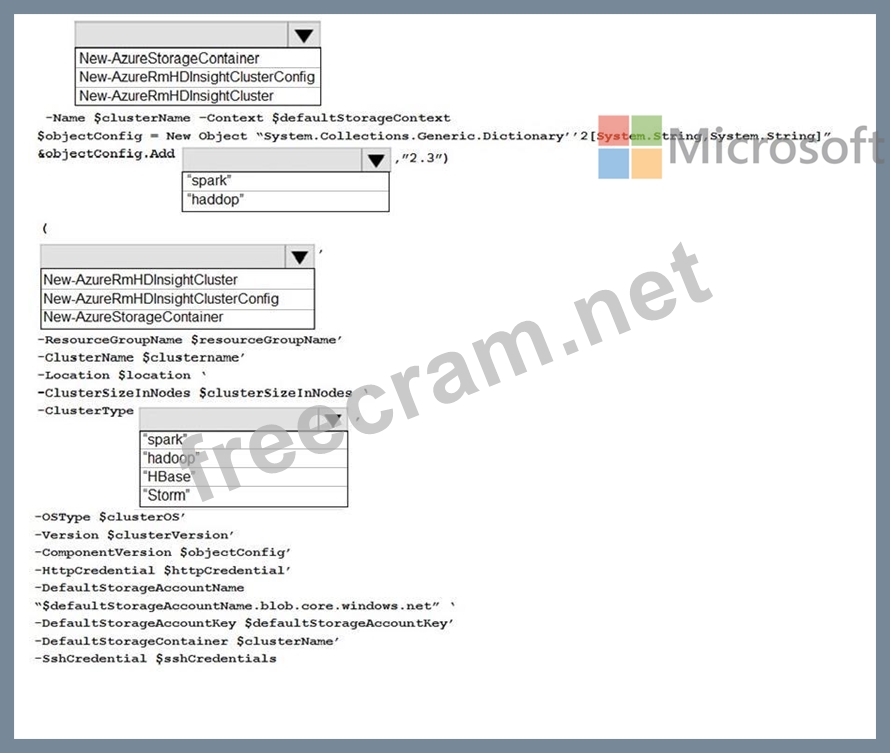
How should you complete the PowerShell segment? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.
A project requires an in-memory batch data processing solution.
You need to provision an HDInsight cluster for batch processing of data on Microsoft Azure.
How should you complete the PowerShell segment? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.
Correct Answer:
Explanation
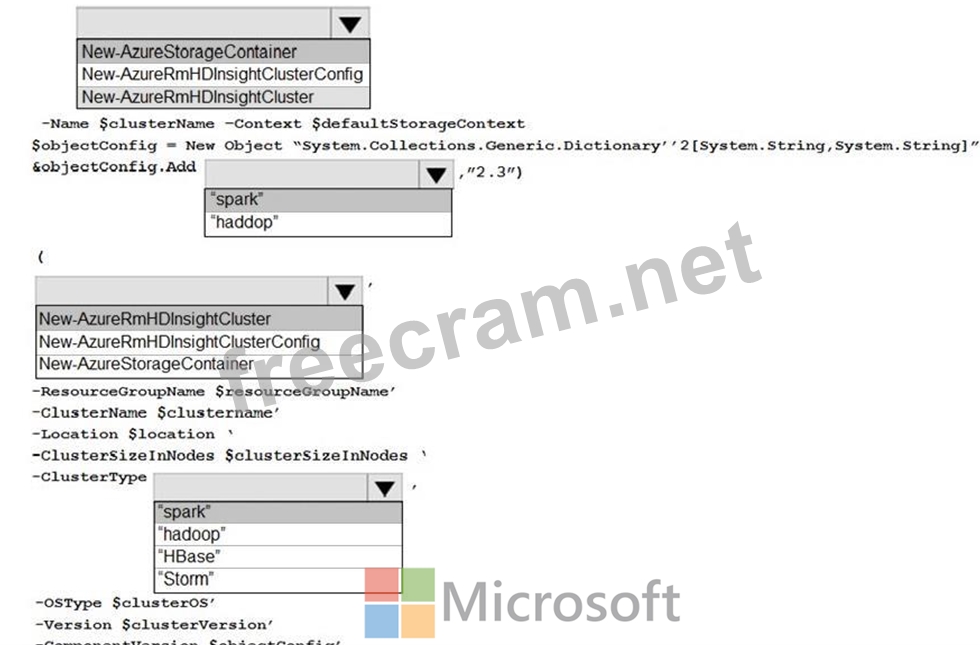
Box 1: New-AzStorageContainer
# Example: Create a blob container. This holds the default data store for the cluster.
New-AzStorageContainer `
-Name $clusterName `
-Context $defaultStorageContext
$sparkConfig = New-Object "System.Collections.Generic.Dictionary``2[System.String,System.String]"
$sparkConfig.Add("spark", "2.3")
Box 2: Spark
Spark provides primitives for in-memory cluster computing. A Spark job can load and cache data into memory and query it repeatedly. In-memory computing is much faster than disk-based applications than disk-based applications, such as Hadoop, which shares data through Hadoop distributed file system (HDFS).
Box 3: New-AzureRMHDInsightCluster
# Create the HDInsight cluster. Example:
New-AzHDInsightCluster `
-ResourceGroupName $resourceGroupName `
-ClusterName $clusterName `
-Location $location `
-ClusterSizeInNodes $clusterSizeInNodes `
-ClusterType $"Spark" `
-OSType "Linux" `
Box 4: Spark
HDInsight is a managed Hadoop service. Use it deploy and manage Hadoop clusters in Azure. For batch processing, you can use Spark, Hive, Hive LLAP, MapReduce.
References:
https://docs.microsoft.com/bs-latn-ba/azure/hdinsight/spark/apache-spark-jupyter-spark-sql-use-powershell
https://docs.microsoft.com/bs-latn-ba/azure/hdinsight/spark/apache-spark-overview
Box 1: New-AzStorageContainer
# Example: Create a blob container. This holds the default data store for the cluster.
New-AzStorageContainer `
-Name $clusterName `
-Context $defaultStorageContext
$sparkConfig = New-Object "System.Collections.Generic.Dictionary``2[System.String,System.String]"
$sparkConfig.Add("spark", "2.3")
Box 2: Spark
Spark provides primitives for in-memory cluster computing. A Spark job can load and cache data into memory and query it repeatedly. In-memory computing is much faster than disk-based applications than disk-based applications, such as Hadoop, which shares data through Hadoop distributed file system (HDFS).
Box 3: New-AzureRMHDInsightCluster
# Create the HDInsight cluster. Example:
New-AzHDInsightCluster `
-ResourceGroupName $resourceGroupName `
-ClusterName $clusterName `
-Location $location `
-ClusterSizeInNodes $clusterSizeInNodes `
-ClusterType $"Spark" `
-OSType "Linux" `
Box 4: Spark
HDInsight is a managed Hadoop service. Use it deploy and manage Hadoop clusters in Azure. For batch processing, you can use Spark, Hive, Hive LLAP, MapReduce.
References:
https://docs.microsoft.com/bs-latn-ba/azure/hdinsight/spark/apache-spark-jupyter-spark-sql-use-powershell
https://docs.microsoft.com/bs-latn-ba/azure/hdinsight/spark/apache-spark-overview


- Question List (80q)
- Question 1: (Exhibit) Use the following login credentials as needed: Azu...
- Question 2: You plan to implement an Azure Cosmos DB database that will ...
- Question 3: A company uses Microsoft Azure SQL Database to store sensiti...
- Question 4: You develop data engineering solutions for a company. You ne...
- Question 5: Note: This question is part of a series of questions that pr...
- Question 6: A company uses Azure SQL Database to store sales transaction...
- Question 7: An application will use Microsoft Azure Cosmos DB as its dat...
- Question 8: You have an Azure Stream Analytics job named ASA1. The Diagn...
- Question 9: You manage a solution that uses Azure HDInsight clusters. Yo...
- Question 10: Note: This question is part of a series of questions that pr...
- Question 11: Note: This question is part of a series of questions that pr...
- Question 12: You develop data engineering solutions for a company. A proj...
- Question 13: Your company uses Azure SQL Database and Azure Blob storage....
- Question 14: You have data stored in thousands of CSV files in Azure Data...
- Question 15: (Exhibit) Use the following login credentials as needed: Azu...
- Question 16: You are a data engineer. You are designing a Hadoop Distribu...
- Question 17: What should you include in the Data Factory pipeline for Rac...
- Question 18: You develop data engineering solutions for a company. You mu...
- Question 19: (Exhibit) Use the following login credentials as needed: Azu...
- Question 20: The data engineering team manages Azure HDInsight clusters. ...
- Question 21: Note: This question is part of a series of questions that pr...
- Question 22: Note: This question is part of a series of questions that pr...
- Question 23: Use the following login credentials as needed: Azure Usernam...
- Question 24: You have a SQL pool in Azure Synapse that contains a table n...
- Question 25: You are developing the data platform for a global retail com...
- Question 26: You need set up the Azure Data Factory JSON definition for T...
- Question 27: You need to collect application metrics, streaming query eve...
- Question 28: Which masking functions should you implement for each column...
- Question 29: A company is designing a hybrid solution to synchronize data...
- Question 30: You have a table named SalesFact in an Azure SQL data wareho...
- Question 31: You are creating a managed data warehouse solution on Micros...
- Question 32: You are a data engineer implementing a lambda architecture o...
- Question 33: Note: This question is part of a series of questions that pr...
- Question 34: You develop data engineering solutions for a company. You ne...
- Question 35: You are processing streaming data from vehicles that pass th...
- Question 36: Note: This question is part of series of questions that pres...
- Question 37: You need to ensure polling data security requirements are me...
- Question 38: A company manages several on-premises Microsoft SQL Server d...
- Question 39: Note: This question is part of a series of questions that pr...
- Question 40: You plan to create a dimension table in Azure Data Warehouse...
- Question 41: You develop data engineering solutions for a company. The co...
- Question 42: You develop data engineering solutions for a company. You mu...
- Question 43: Use the following login credentials as needed: Azure Usernam...
- Question 44: You have an enterprise data warehouse in Azure Synapse Analy...
- Question 45: You need to implement event processing by using Stream Analy...
- Question 46: Note: This question is part of a series of questions that pr...
- Question 47: You need to build a solution to collect the telemetry data f...
- Question 48: You have an Azure Data Factory that contains 10 pipelines. Y...
- Question 49: Note: This question is part of a series of questions that pr...
- Question 50: A company plans to use Azure Storage for file storage purpos...
- Question 51: You are monitoring an Azure Stream Analytics job. You discov...
- Question 52: You plan to deploy an Azure Cosmos DB database that supports...
- Question 53: You develop data engineering solutions for a company. A proj...
- Question 54: You configure monitoring for a Microsoft Azure SQL Data Ware...
- Question 55: You use Azure Stream Analytics to receive Twitter data from ...
- Question 56: You are implementing Azure Stream Analytics functions. Which...
- Question 57: You have an Azure Storage account and an Azure SQL data ware...
- Question 58: You need to implement the encryption for SALESDB. Which thre...
- Question 59: A company has a real-lime data analysis solution that is hos...
- Question 60: Note: This question is part of a series of questions that pr...
- Question 61: Note: This question is part of a series of questions that pr...
- Question 62: You manage an enterprise data warehouse in Azure Synapse Ana...
- Question 63: You are implementing automatic tuning mode for Azure SQL dat...
- Question 64: Note: This question is part of a series of questions that pr...
- Question 65: Note: This question is part of a series of questions that pr...
- Question 66: You have an Azure data factory that has two pipelines named ...
- Question 67: You have an Azure SQL data warehouse. Using PolyBase, you cr...
- Question 68: You are developing a solution that will stream to Azure Stre...
- Question 69: You manage a process that performs analysis of daily web tra...
- Question 70: (Exhibit) Use the following login credentials as needed: Azu...
- Question 71: You have an Azure Cosmos DB database that uses the SQL API. ...
- Question 72: Your company uses Microsoft Azure SQL Database configure wit...
- Question 73: Note: This question is part of series of questions that pres...
- Question 74: You manage a Microsoft Azure SQL Data Warehouse Gen 2. Users...
- Question 75: Note: This question is part of series of questions that pres...
- Question 76: You are building the data store solution for Mechanical Work...
- Question 77: You are building an Azure Stream Analytics query that will r...
- Question 78: You have an ASP.NET web app that uses an Azure SQL database....
- Question 79: You are monitoring the Data Factory pipeline that runs from ...
- Question 80: You are developing a solution to visualize multiple terabyte...
