<< Prev Question Next Question >>
Question 31/51
You are designing an Al solution that must meet the following processing requirements:
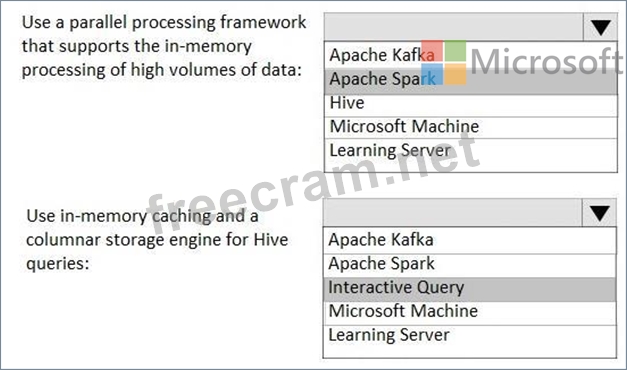
* Use a parallel processing framework that supports the in-memory processing of high volumes of data.
* Use in-memory caching and a columnar storage engine for Apache Hive queries.
What should you use to meet each requirement? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.

* Use a parallel processing framework that supports the in-memory processing of high volumes of data.
* Use in-memory caching and a columnar storage engine for Apache Hive queries.
What should you use to meet each requirement? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.