Valid DA0-001 Dumps shared by ExamDiscuss.com for Helping Passing DA0-001 Exam! ExamDiscuss.com now offer the newest DA0-001 exam dumps, the ExamDiscuss.com DA0-001 exam questions have been updated and answers have been corrected get the newest ExamDiscuss.com DA0-001 dumps with Test Engine here:
Access DA0-001 Dumps Premium Version
(398 Q&As Dumps, 35%OFF Special Discount Code: freecram)
<< Prev Question Next Question >>
Question 146/160
Given the following data set:
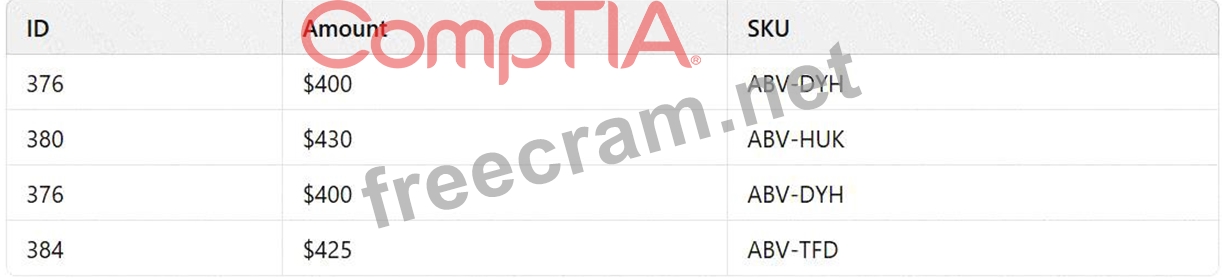
Which of the following is the best reason for cleansing the data?
Which of the following is the best reason for cleansing the data?
Correct Answer: A
Comprehensive and Detailed In-Depth Explanation:
In data management,duplicate datarefers to identical records that appear multiple times within a dataset. Such duplicates can lead to inaccurate analyses, inflated metrics, and erroneous business decisions. Identifying and removing duplicate records is a critical step in the data cleansing process to ensure data quality and reliability.
Option A:Duplicate data
* Rationale:The dataset shows that the record with ID 376, Amount $400, and SKU ABV-DYH appears twice. This repetition indicates the presence of duplicate data, which can skew analysis results if not addressed.
Option B:Imputed data
* Rationale:Imputed data refers to missing or incomplete data that has been estimated or filled in based on other available information. There is no evidence in the provided dataset to suggest that any data has been imputed.
Option C:Redundant data
* Rationale:Redundant data involves unnecessary repetition of data across different fields or tables, leading to inefficiencies. While duplicate data is a form of redundancy, in this context, the specific issue is the exact repetition of entire records, making "duplicate data" the more precise term.
Option D:Corrupt data
* Rationale:Corrupt data refers to data that has been altered or damaged, making it incorrect or unusable.
The dataset provided does not exhibit signs of corruption, such as garbled text or invalid formats.
In data management,duplicate datarefers to identical records that appear multiple times within a dataset. Such duplicates can lead to inaccurate analyses, inflated metrics, and erroneous business decisions. Identifying and removing duplicate records is a critical step in the data cleansing process to ensure data quality and reliability.
Option A:Duplicate data
* Rationale:The dataset shows that the record with ID 376, Amount $400, and SKU ABV-DYH appears twice. This repetition indicates the presence of duplicate data, which can skew analysis results if not addressed.
Option B:Imputed data
* Rationale:Imputed data refers to missing or incomplete data that has been estimated or filled in based on other available information. There is no evidence in the provided dataset to suggest that any data has been imputed.
Option C:Redundant data
* Rationale:Redundant data involves unnecessary repetition of data across different fields or tables, leading to inefficiencies. While duplicate data is a form of redundancy, in this context, the specific issue is the exact repetition of entire records, making "duplicate data" the more precise term.
Option D:Corrupt data
* Rationale:Corrupt data refers to data that has been altered or damaged, making it incorrect or unusable.
The dataset provided does not exhibit signs of corruption, such as garbled text or invalid formats.


- Question List (160q)
- Question 1: An analyst is designing a dashboard to determine which site ...
- Question 2: Which one of the following is a common data warehouse schema...
- Question 3: A data analyst is creating a report that will provide inform...
- Question 4: A military commander would like to see the health scorecards...
- Question 5: Which of the following is an example of a discrete variable?...
- Question 6: A data analyst reviews the following data set: (Exhibit) Whi...
- Question 7: Which of the following is an example of a discrete data type...
- Question 8: An analyst wants to combine two data sets into a single spre...
- Question 9: Which of the following is most likely to be used as a data-m...
- Question 10: Which of the following are reasons to conduct data cleansing...
- Question 11: A Chief Executive Officer (CEO) is requesting more up-to-dat...
- Question 12: Which of the following is the best approach to use to gain a...
- Question 13: Which of the following is a KPI metric for tracking sales pe...
- Question 14: The number of phone calls that the call center receives in a...
- Question 15: Which of the following types of analysis is used when compar...
- Question 16: Which of the following is the most appropriate to consider w...
- Question 17: Which of the following is a control measure for preventing a...
- Question 18: Which of the following best describes a business analytics t...
- Question 19: A data analyst is attempting to understand how ice cream con...
- Question 20: You are working with a professional statistician to perform ...
- Question 21: A data analyst for a media company needs to determine the mo...
- Question 22: A sales manager wants quarterly sales reports broken down by...
- Question 23: What SQL command is used to delete an entire table from a da...
- Question 24: A marketing analytics team received customer transaction dat...
- Question 25: An analyst is creating a resource to improve users' experien...
- Question 26: Which of the following is an example of a flat file?...
- Question 27: A healthcare data analyst notices that one data set in the c...
- Question 28: Which of the following statements would be used to append tw...
- Question 29: Q3 2020 has just ended, and now a data analyst needs to crea...
- Question 30: An analyst is working on a project for a director. During th...
- Question 31: An analyst is required to run a text analysis of data that i...
- Question 32: Which of the following variable name formats would be proble...
- Question 33: A sales manager requested a report that contains the first n...
- Question 34: A data analyst has received a data set that contains actual ...
- Question 35: A data analyst has a set of data that shows the number of ga...
- Question 36: Which of the following data governance concepts fits into th...
- Question 37: Which of the following is a non-parametric test?...
- Question 38: Which of the following is an example of structured data?...
- Question 39: An analyst is building a new dashboard for a user. After an ...
- Question 40: After the daily ETL jobs are completed, the data in the repo...
- Question 41: Given the following data sample: (Exhibit) Which of the foll...
- Question 42: Which of the following concepts should be applied if a data ...
- Question 43: Which of the following data types must be used when working ...
- Question 44: The total values in this month's revenue report are twice as...
- Question 45: Jenny wants to study the academic performance of undergradua...
- Question 46: Which of the following data types would a telephone number f...
- Question 47: An analyst has received the requirements for an internal use...
- Question 48: A database administrator needs to ensure only approved users...
- Question 49: A data analyst is developing a dashboard to track and monito...
- Question 50: Given the table below: (Exhibit) Which of the following vari...
- Question 51: Which of the following data sampling methods involves dividi...
- Question 52: A company wants to know how its customers interact with an e...
- Question 53: A data analyst received the information in the table below f...
- Question 54: A data analyst wants to create "Income Categories" that woul...
- Question 55: Which of the following data types best describe 4Ac1? (Selec...
- Question 56: Which of the following occurs if a 90% confidence interval i...
- Question 57: Which of the following report types is most appropriate for ...
- Question 58: What subset of Structured Query Language (SQL) is used to ad...
- Question 59: A data analyst is asked to create a sales report for the sec...
- Question 60: Which of the following statistical methods requires two or m...
- Question 61: A data analyst must separate the column shown below into mul...
- Question 62: A research analyst collects ten data points from 1.000 speci...
- Question 63: A data analyst has been asked to organize the table below in...
- Question 64: A data analyst has been asked to create a daily manufacturin...
- Question 65: A data analyst is setting up a data dashboard to monitor sev...
- Question 66: A table in a hospital database has a column for patient heig...
- Question 67: A data analyst needs to write a SOL query measuring last mon...
- Question 68: Each month an analyst needs to execute a data pull for the t...
- Question 69: A stakeholder wants to see daily sales targets organized in ...
- Question 70: A data set was recorded using multimedia technology. Which o...
- Question 71: A development company is constructing a new Init in its apar...
- Question 72: Which of the following is an object associated with a table ...
- Question 73: Which of the following would be considered non-personally id...
- Question 74: A data analyst is developing a data dictionary that aligns w...
- Question 75: Which of the following is used for calculations and pivot ta...
- Question 76: A financial institution is reporting on sales performance to...
- Question 77: An analyst is updating a customer contacts database with inf...
- Question 78: An organization would like to add a secondary email field to...
- Question 79: Given the image below: (Exhibit) The data should be cleaned ...
- Question 80: Which of the following actions should be taken when transmit...
- Question 81: A data analyst needs to create a dashboard using the company...
- Question 82: Given the following: (Exhibit) Which of the following is the...
- Question 83: Which of the following are the first steps a company should ...
- Question 84: An analyst notices changes in sales ratios when analyzing a ...
- Question 85: Given the following table: (Exhibit) Which of the following ...
- Question 86: A data analyst has been asked to derive a new variable label...
- Question 87: Which of the following should be accomplished NEXT after und...
- Question 88: A research analyst wants to determine whether the data being...
- Question 89: An analyst has been tracking company intranet usage and has ...
- Question 90: An analyst reviews the following table: (Exhibit) Which of t...
- Question 91: Which of the following activities occurs during the ETL proc...
- Question 92: An analyst has been asked to validate data quality. Which of...
- Question 93: Which of the following query optimization techniques involve...
- Question 94: An analyst needs to join two tables of data together for ana...
- Question 95: Which one of the following in NOT a common data integration ...
- Question 96: A data analyst needs to observe the relationship between two...
- Question 97: A database administrator needs to increase performance on a ...
- Question 98: A sales team wants visibility of current sales numbers, pipe...
- Question 99: Which of the following describes the method of sampling in w...
- Question 100: A data analyst received a large amount of third-party data t...
- Question 101: Which of the following tools would be best to use to calcula...
- Question 102: A data scientist wants to see which products make the most m...
- Question 103: Angela is aggregating data from CRM system with data from an...
- Question 104: Which of the following is the best reason to use database vi...
- Question 105: Which of the following explains why standardization of data ...
- Question 106: An analyst reviews the following data: 7 3 5 2 3 7 7 10 Whic...
- Question 107: The duration of a phone call in milliseconds is an example o...
- Question 108: You are working with a dataset and want to change the names ...
- Question 109: Which of the following data governance concepts fits into th...
- Question 110: Which of the following descriptive statistical methods are m...
- Question 111: Given the following graph: (Exhibit) Which of the following ...
- Question 112: During data cleansing, an analyst conducts measures of centr...
- Question 113: A data analyst is creating a dashboard and trying to identif...
- Question 114: The process of performing initial investigations on data to ...
- Question 115: Which of the following best describes how discrete data diff...
- Question 116: A data analyst needs to perform a full outer join of a custo...
- Question 117: A data analyst is working with a team to create a dashboard ...
- Question 118: You would like to measure how well an organization is achiev...
- Question 119: While reviewing survey data, an analyst notices respondents ...
- Question 120: Which of the following is a difference between a primary key...
- Question 121: A sales director has requested a report for individual team ...
- Question 122: A data analyst was asked to create a chart that shows the re...
- Question 123: An analyst runs a report on a daily basis, and the number of...
- Question 124: Which of the following data types is best for representing c...
- Question 125: A recurring event is being stored in two databases that are ...
- Question 126: A database administrator is required to mask certain table c...
- Question 127: Daniel is using the structured Query language to work with d...
- Question 128: Given the diagram below: (Exhibit) Which of the following st...
- Question 129: Given the image below: (Exhibit) Which of the following file...
- Question 130: A survey asks participants to rate a company on a scale of o...
- Question 131: Which of the following is a best practice when updating a le...
- Question 132: A business intelligence team wants to create a new dashboard...
- Question 133: A data analyst has been asked to create an ad-hoc sales repo...
- Question 134: Which one the following is not considered an aggregate funct...
- Question 135: An analyst is preparing a report that contains weather data....
- Question 136: Which of the following BEST describes standard deviation?...
- Question 137: Given the table below: (Exhibit) Which of the following boxe...
- Question 138: A data analyst needs to create a master file that includes c...
- Question 139: An analysts building a monthly report for production and wan...
- Question 140: Given the diagram below: (Exhibit) Which of the following ty...
- Question 141: Which of the following should an analyst do to best summariz...
- Question 142: An analyst modified a data set that had a number of issues. ...
- Question 143: Which of the following is an example of a at flat file?...
- Question 144: A sales analyst needs to report how the sales team is perfor...
- Question 145: Taylor wants to investigate how manufacturing, marketing, an...
- Question 146: Given the following data set: (Exhibit) Which of the followi...
- Question 147: Alex wants to use data from his corporate sale, CRM, and shi...
- Question 148: Which of the following is a domain-specific language used in...
- Question 149: A data analyst has a set with more than 40.000 rows in the s...
- Question 150: Given the following grocery store orders: (Exhibit) If a que...
- Question 151: What role in a data governance is typically responsible for ...
- Question 152: You should always choose the analytics tool that is most app...
- Question 153: Given the data below: (Exhibit) In which of the following fi...
- Question 154: A user receives a large custom report to track company sales...
- Question 155: A data analyst is working for a shipping company and calcula...
- Question 156: A data analyst needs to present the results of an online mar...
- Question 157: Which of the following is the best description of the term "...
- Question 158: A junior web developer is developing a new application where...
- Question 159: Amanda needs to create a dashboard that will draw informatio...
- Question 160: Which of the following is the best variable formal to store ...
